

Stop Building AI That Forgets
A framework for AI systems that get better over time, not just perform on demand.




This week’s piece comes from Chandra Prakash (CP), who builds AI systems that run content operations without him and documents the architecture publicly.
TL;DR- In this post, CP breaks down why your AI tool takes input, produces output, and starts from zero next session — and lays out the three properties that make an AI system compound over time: persistent structured memory (not conversation logs), state management separated from the conversation layer, and trigger-based automation that acts without being prompted. He walks through a production build (DAKS, on Telegram, n8n, and Supabase) and gives you a three-question diagnostic to test whether your own systems execute or compound.
The case study is a personal accountability bot, but the architecture pattern applies anywhere context accumulates: customer onboarding, recurring project workflows, ongoing advisory relationships.
Over to him!

AI Systems That Compound: An Architecture Framework
Most AI implementations answer one question, then forget it was asked.
You feed them input. They produce output. The interaction ends. The next session starts from zero. Nothing accumulates. Nothing compounds.
This is the default state of AI tooling in 2026 — not because the models are limited, but because most implementations are designed for execution, not accumulation.
There is a meaningful architectural difference between an AI system that executes and one that compounds. It’s not about the model. It’s about what the system retains, how it routes decisions, and whether each interaction makes the next one more useful.
This piece breaks down that difference — and what it takes to build the second kind.
The Execution Trap
An execution system takes input, produces output, and terminates. It doesn’t know what happened last time. It doesn’t know what worked. It doesn’t adapt to the user’s context over time.
Most enterprise AI implementations fall here by default. A chatbot answers questions. A summariser processes documents. A classifier labels inputs. Each task is completed correctly. Nothing builds on anything else.
The problem isn’t accuracy. It’s architecture. These systems are designed to close the loop after every interaction — which makes them reliable but flat. They perform consistently without improving.
For one-off tasks, that’s fine. For any system where context accumulates over time — customer relationships, ongoing projects, recurring workflows — it’s a ceiling.
The Three Properties of a Compounding System
An AI system compounds when it has three architectural properties working together.
Property 1: Persistent memory with structured retrieval
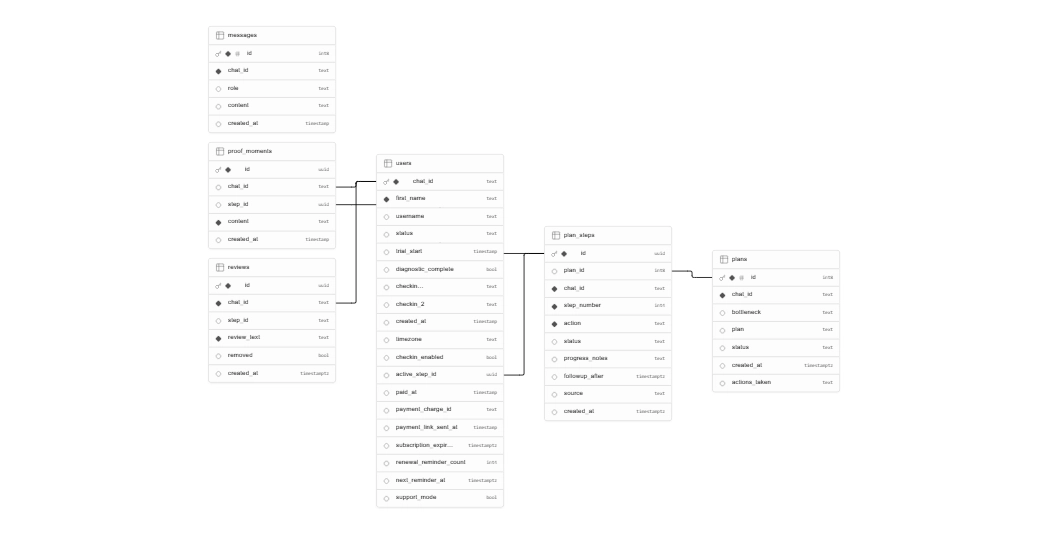
The system must retain what happened and make it accessible in a structured way — not as a raw log, but as a queryable state. The difference matters. A raw conversation log is noise. A structured state tells the system: here is what this user committed to, here is what they’ve completed, here is where they currently are.
In practice, this requires an external database — not a context window. Context windows reset. Databases don’t.
The implementation: a purpose-built schema that captures the information the system actually needs to make the next interaction more useful. Not everything. The right things.
Property 2: State management separate from conversation
Most AI implementations conflate the conversation layer with the state layer. The model handles both — which means state gets lost when the conversation ends.
A compounding system separates them. The conversation layer handles input and output. A dedicated state manager runs after every interaction, parses what happened, and updates the external record. The model doesn’t manage state. It reads state.
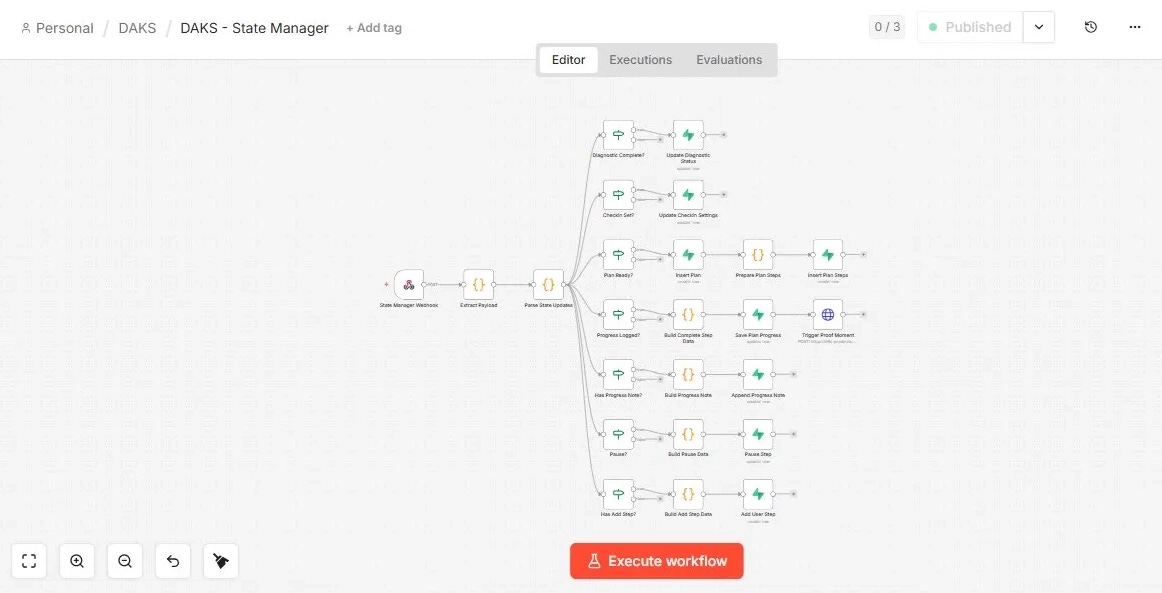
This separation is what allows the system to pick up exactly where it left off — not by re-reading a transcript, but by loading a current record of what’s true.
Property 3: Trigger-based automation that doesn’t require presence
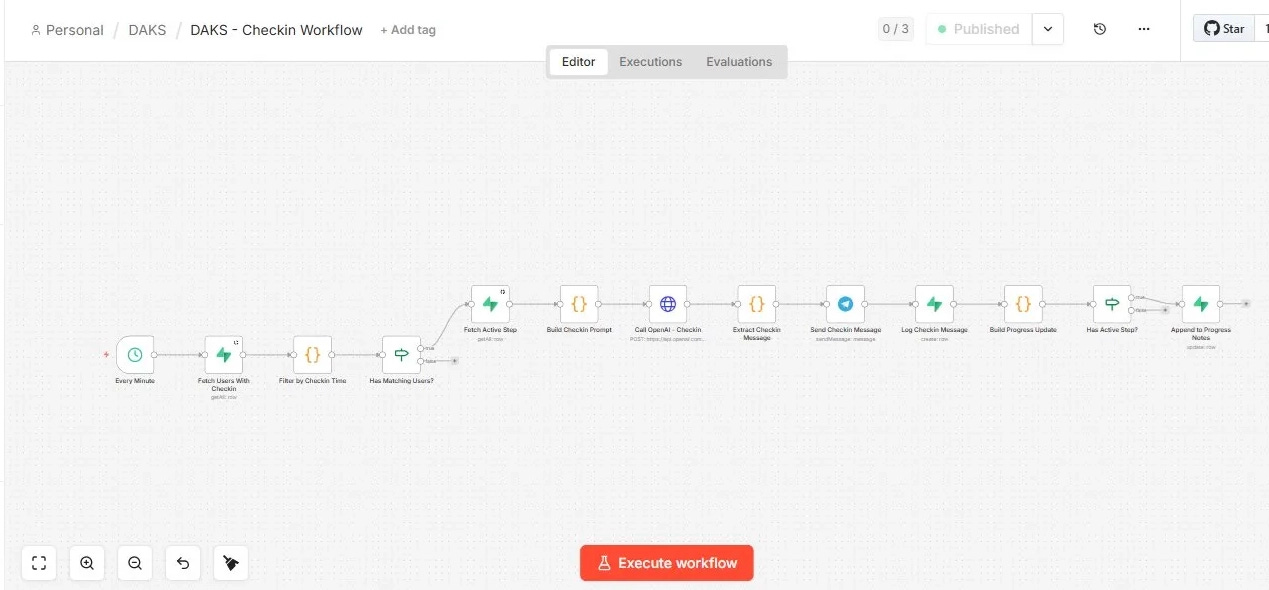
An execution system responds when prompted. A compounding system acts on schedule — because the most valuable interventions happen at the right time, not when the user remembers to ask.
This requires a separate automation layer — scheduled workflows that read state, determine what’s relevant, construct context-aware prompts, and act without waiting for input. The intelligence isn’t in the model. It’s in the trigger logic.
A Production Implementation
These three properties are easier to illustrate in a working system than as abstract architecture.
DAKS is an AI accountability system built on Telegram, n8n, GPT-4o, and Supabase. The architecture maps directly to the three properties above.
Persistent memory: Every user interaction is logged to Supabase across three tables — users, messages, plans. When a returning user sends a message, the system doesn’t re-read their conversation history. It loads their current plan, their active step, and their recent progress — structured state, not a transcript. The model receives exactly what it needs to respond with context. Nothing more.
State management: A dedicated State Manager workflow runs after every conversation. It parses what happened — did the user complete a step, set a check-in time, or update their plan? — and writes the result to Supabase. The conversation model doesn’t track this. It executes against whatever state the workflow maintains.
Trigger-based automation: A Check-in Workflow runs every minute. It queries Supabase for users whose check-in time matches the current time in their timezone, loads their active plan step, constructs a context-aware prompt, calls the model, and sends the message via Telegram. No human triggers this. No user has to remember to ask. The system acts because the schedule says to — and it knows what to say because the state is current.
The result: a system that knows more about each user’s situation after four weeks than it did after one — without any manual maintenance. The database accumulates. The state manager keeps it current. The automation layer acts on it.
That’s compounding. Not metaphorically. Architecturally.
CP documents every architecture decision, cost, and failure from building Donna (his autonomous content system) in public. If you want to follow the build in real time:

The Diagnostic: Does Your AI System Compound?
Three questions to evaluate any AI implementation:
1. What does the system retain between sessions?
If the answer is “nothing” or “a conversation transcript,” the system executes but doesn’t compound. Compounding requires structured state — specific, queryable records of what matters.
2. Who manages state — the model or a dedicated layer?
If the model is handling both conversation and state, state will degrade over long interactions as context fills. Compounding systems separate these concerns explicitly.
3. Does the system act without being prompted?
If the system only responds to input, it’s execution-mode. Compounding systems have trigger logic — scheduled or event-based — that acts based on what the state says, not on whether someone asked.
The Build Sequence
Start with the state schema. Before you write a single prompt, decide what information the system needs to retain to make future interactions more useful. This is the hardest design decision — and the one most teams skip.
Then build the conversation layer against that schema. The model reads state before responding. It doesn’t manage state. Keep these concerns separate from the start.
Then add the state manager. After every interaction, something updates the record. It needs to be reliable. Missed state updates degrade the system faster than any model limitation.
Trigger-based automation comes last. It’s the highest-leverage layer but requires accurate state to work. Build it on top of a system that already knows where every user is.
What This Means for AI Investment Decisions
When evaluating AI systems — whether building, buying, or advising — the compounding question is the right frame.
A system that executes reliably has value proportional to the task. A system that compounds has value that increases over time. The second type is harder to build but returns differently — each interaction makes the next one more valuable, which changes the unit economics of deployment entirely.
Most AI vendor pitches don’t distinguish between these. They demonstrate execution — accurate, fast, impressive in a demo. The architecture question — what does this system retain, and how does it use it — rarely comes up in a PoC.
It’s the right question to ask first.
Our Take
CP’s framework names something we see constantly in AI implementations: the gap between “this works” and “this gets better over time.”
The three-property model works as a diagnostic. Next time you’re evaluating an AI tool or building a workflow, run the checklist: What does it retain between sessions? Who manages state, the model or a separate layer? Does it act without being prompted? Tools fail on all three more often than not. Knowing that upfront saves you from expecting compounding behavior from an execution architecture.
The hard part is the state schema: deciding what to retain and what to ignore. CP flags this as the hardest design decision, and we agree. Get that wrong, and persistent memory becomes persistent noise. If you’re building something like this, start with the smallest useful state: what three things does the system need to know about this user to make the next interaction 20% better? Build from there.
We've built against the same pattern. Our two-part autonomous content system series (Part 1: persistent memory, Part 2: automation pipeline) uses Claude Code and Notion via MCP instead of Supabase and Telegram, but the architecture mirrors CP's three properties.

If you want to see our version of this, start there. And if you want the cost side of the equation before committing, The Agent Tax breaks down what these workflows actually cost at scale.

Everything we build lives in the Cash & Cache Library.
Skill files, AI workflow templates, prompt packs, and implementation guides — all downloadable, all built from how we actually work. Premium subscribers get full access.
Unlock the Library → Cash & Cache Library
CP documents the build process for Donna, his autonomous content system, on his Substack. If you want to see these architecture patterns applied to a live system with real costs and real failures, that’s where he’s publishing the work.
Want to watch AI workflows built in real time, not just read about them?
I’m part of Cozora. A practitioner community where people teach real AI implementation live. Not theory. Actual workflows you can apply the same day.
Cash & Cache subscribers get 10% discount to join.
What AI system are you running right now that resets to zero every session? And what would it look like if it didn't? Leave a comment.

💡 Enjoying this article or other ones about AI implementation? Share this piece with someone who can benefit.
 | A guest post by
|
The separation between conversation and state management is explained really well here.
The hard part usually starts after persistent state begins accumulating for months across real workflows. Schemas drift, priorities change, stale assumptions stay in memory, and eventually someone has to decide what the system should forget, overwrite, or stop acting on.
Compounding systems can compound noise too if the operational ownership around state isn’t clear.