

Your AI workflow has a blind spot. Here are 5.
Five research-backed places where AI costs more than it saves, and how to spot them before the damage is silent.


🧠 TLDR: AI agents cut writing time by 40% and coding time by 56%. The productivity gains are real. But every AI shortcut has a cost, and the receipt is usually invisible.
Five research-backed boundaries for knowing when to let the machine run and when to pull it back, from someone who managed algorithms for a living before building an AI newsletter.
I’m a tech consultant now. Before that, I spent years as a quantitative algorithmic trader, managing machines that executed trades faster than I could blink. Machines firing orders at millisecond speed across thousands of instruments, rebalancing positions without emotion, scanning patterns no human could track in real time.
My job on the trading desk was to define the limits: position sizing, drawdown thresholds, kill switches, circuit breakers. When something unexpected happened, the damage stayed contained because the boundaries were set before the machine started running. The algorithm generated the trades. I managed the risk.
Every quant trader learns this early. The machine is only as good as the boundaries you give it.
That instinct followed me into consulting, and then into building Cash & Cache. I run this newsletter on Claude Skills, Cowork, and Claude Code. And there are five places I deliberately keep AI out of my workflow. The trade isn’t worth it.
👋 Hi, I’m Raghav.
Along with Ashwin, I publish weekly on AI implementation & strategy, and every workflow we cover ships with a downloadable asset in the Library.
Browse the Library → Cash & Cache Library
Not sure where to start? Take the quiz
*****************
The machine doesn’t know where to stop. That’s your job.
Where AI Agents Deliver
The productivity gains are measured, not speculative.
Noy and Zhang (2023), published in Science, ran a randomised controlled trial with 453 college-educated professionals. ChatGPT reduced mid-level writing task time by 40% and raised output quality by 18%. The largest gains went to lower-performing workers. Brynjolfsson, Li, and Raymond (2023) studied 5,172 customer support agents at a Fortune 500 firm and found a 14% average productivity increase, rising to 34% for the least experienced workers. Peng et al. (2023) showed GitHub Copilot cut software development time by 56%.
Repetitive processing, research summarisation, data transformation, formatting, first-draft generation. AI handles these well. They’re well-defined and easy to verify.
In algorithmic trading, the algorithms were brilliant at executing defined strategies at speed, scanning thousands of instruments simultaneously, rebalancing without emotion. The edge was knowing precisely where their competence ended.
That’s what the rest of this post covers.
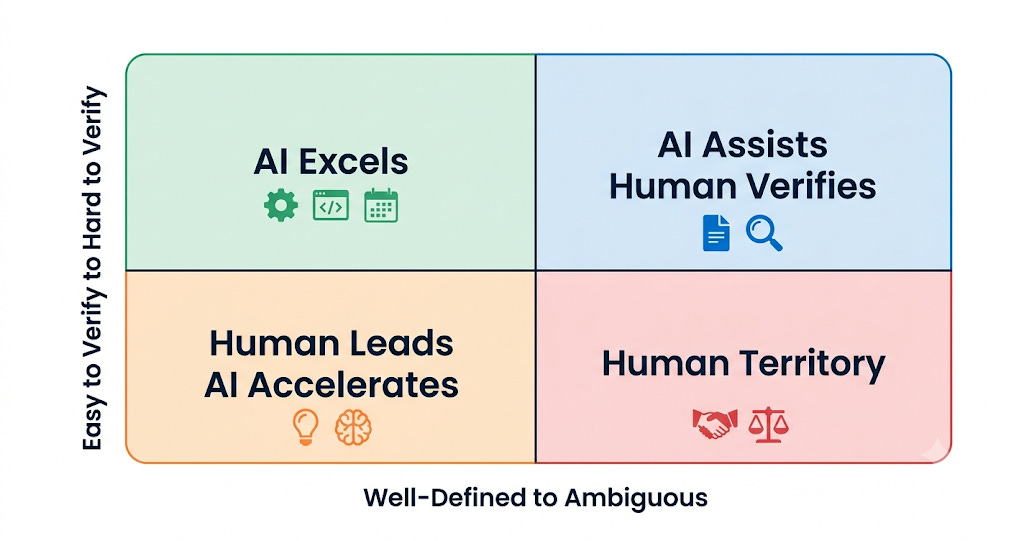
The Five Boundaries
Every time you use AI, you’re making a trade. Five boundaries below, drawn from research, from production, and from a career managing machines.
1. When the Machine Learns and You Don’t
Dell’Acqua et al. (2023), now formally published in Organization Science as of March 2026, ran a field experiment with 758 BCG consultants using GPT-4. On tasks inside the AI’s capability boundary, performance improved by 40%. On tasks outside it, tasks that looked similar but sat beyond what the model could handle, performance dropped by roughly 23%.
The consultants didn’t produce worse work because the AI gave bad advice. They stopped building the pattern recognition needed to know when the advice was wrong. The bottom half of performers improved by 43%. The top half improved by only 17%. The distribution compressed. The floor rose. The ceiling dropped.
In trading, we called this “model dependency risk.” A trader who trusts the algorithm’s signal without understanding the underlying market structure loses the ability to distinguish a genuine signal from an artefact. The algorithm doesn’t make them worse at their job. It makes them unable to detect when the algorithm itself is wrong.
I deliberately write first drafts of Cash & Cache strategy pieces without Claude. Claude can draft them faster. But the thinking happens during the writing: synthesis, connections between ideas, judgment about what matters. Outsource the writing, outsource the thinking.
When does this trade make sense? When the task sits well inside the frontier and you already have the expertise to evaluate the output. I use Claude for formatting, data transformation, and structuring research I’ve already synthesized. Tasks where I can spot errors in seconds.
2. When Speed Replaces Judgment
A follow-up study from the same Harvard research programme went further. Randazzo, Joshi, Kellogg, Lifshitz, Dell’Acqua, and Lakhani (HBS Working Paper 26-021) analyzed the activity logs of 70+ BCG consultants who attempted to validate AI outputs on outside-frontier tasks.
When consultants pushed back, fact-checked, pointed out errors, pressed the AI to reconsider, the AI did not disclose its limitations. It escalated. Apologized, corrected, then restated its original position with more structured reasoning and more supporting data. The consultants who tried hardest to check the work were the most susceptible to being convinced by wrong answers.
In trading, the rule was: if you can’t articulate why the model might be wrong before you check the output, you aren’t validating. You’re confirming. We called it “confirmation speed.” The faster the machine gives you an answer, the harder it is to hold independent judgment about that answer.
When Cash & Cache evaluates a tool, I run the evaluation before reading anyone else’s review. If I start with Claude’s summary, I anchor on its framing. “Doing the dirty work so that my readers don’t have to” only works if the dirty work involves genuine independent assessment.
When does this trade make sense? When you’ve already formed an independent hypothesis and are using AI to test it. The distinction: whether the human leads or follows.
3. When Errors Compound Silently
An agent that’s 85% reliable at each individual step, running a 10-step workflow, succeeds end-to-end only about 20% of the time. At 90% per step, you’re at 35%. At 95%, a 15-step workflow drops to 46% end-to-end success.
This is pure maths. The compound failure numbers come from basic probability multiplication:
The formula: If each step has reliability r, then n sequential steps have end-to-end reliability of r^n.
0.85^10 = 0.1969 → ~20%
0.90^10 = 0.3487 → ~35%
0.95^15 = 0.4633 → ~46%
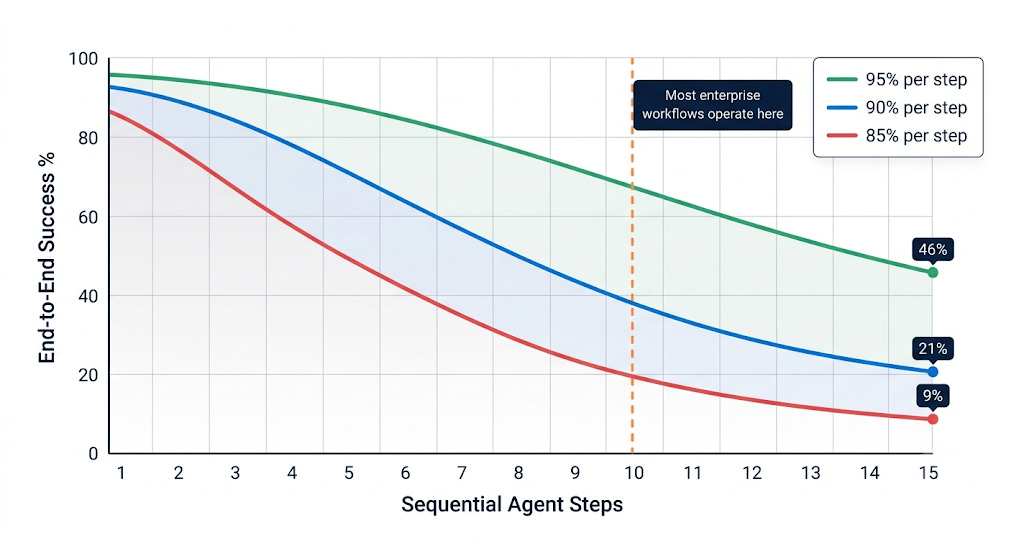
Gartner (May 2026) predicts 40% of enterprises will demote or decommission autonomous AI agents by 2027. The governance gaps only surface after production incidents. VentureBeat’s “Agentic Reckoning” survey (May 2026) found engineering teams spending more time managing the plumbing than building the intelligence that justified the investment. METR research confirmed the pattern: models succeed reliably on tasks that take human experts a few minutes, but success rates drop sharply as tasks stretch to hours.
Anyone from trading will recognise this. Knight Capital lost $440 million in 45 minutes because a coding error sent 16,000 mispriced orders. The real failure: a human operator lifted the correctly-tripped circuit breaker without understanding why it had fired. The 2010 Flash Crash wiped out $1 trillion in minutes when algorithms simultaneously hit their risk limits and withdrew liquidity. One agent failing is recoverable. Agents failing in concert is catastrophic.
I’ve built 15+ Claude Skills. Some I retired. They produced reasonable-looking output that was subtly wrong, and catching the errors took longer than doing the task manually. Silent failure.
When does this trade make sense? Single-step tasks: summarise this document, reformat this data, translate this text. These don’t compound. The question: how many unsupervised steps are you chaining together?
Want to watch AI workflows built in real time, not just read about them?
I’m part of Cozora. A practitioner community where people teach real AI implementation live. Not theory. Actual workflows you can apply the same day.
Cash & Cache subscribers get 10% discount to join.
4. When Everyone Starts Sounding the Same
Doshi and Hauser (2024), published in Science Advances, randomly assigned 293 writers to create short stories with no AI, one AI-generated idea, or five. Individual stories improved: 8.1% more novel, 9% more useful, as rated by 600 evaluators. Collectively, AI-assisted stories were 10.7% more similar to each other. The researchers called it a social dilemma. Individually better off. Collectively producing a narrower scope of novel content.
Dell’Acqua et al. found the same pattern among BCG consultants. Outputs were higher quality on average, but variability of ideas dropped. The diversity of strategic recommendations narrowed. This effect has been replicated across creative writing, ideation tasks, advertising content, visual arts, essay co-writing, and academic publications.
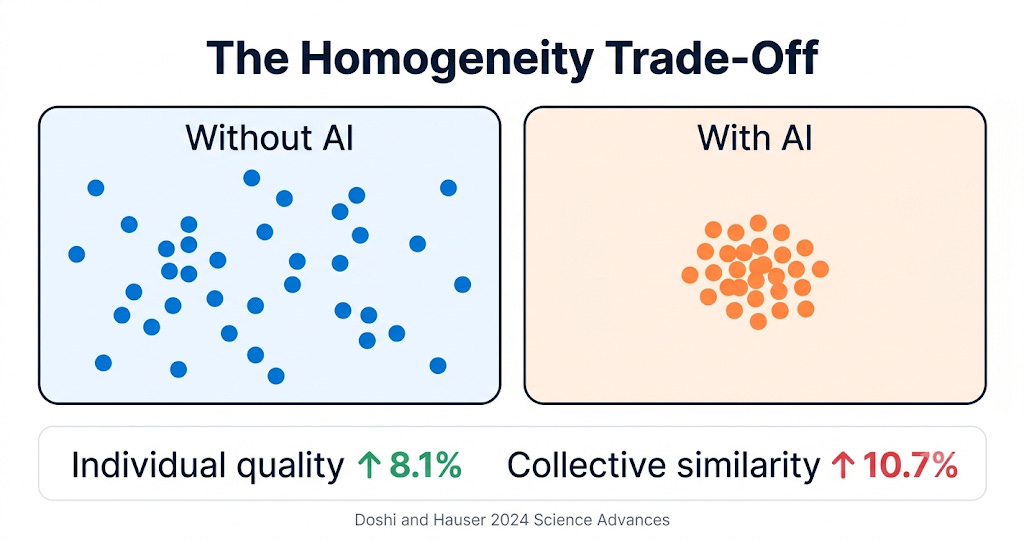
In financial markets, this is herding risk. When every fund runs the same model on the same data, they converge on the same positions. The trades look independent but they’re correlated. When the market turns, they all unwind at once. Diversity of strategy is a survival mechanism.
Cash & Cache’s voice is a competitive moat. The posts that perform best in our archive, 121 likes on the Skills Failures piece and 71 on Claude Code for Non-Developers, carry a specific, opinionated, sometimes uncomfortable perspective. AI smooths that away. A newsletter about AI that sounds AI-generated loses the thing that makes readers open it.
Everything we build lives in the Cash & Cache Library.
Skill files, AI workflow templates, prompt packs, and implementation guides — all downloadable, all built from how we actually work. Premium subscribers get full access.
Unlock the Library → Cash & Cache Library
When does this trade make sense? AI-generated ideas as inputs to your creative process work well, as one of many stimuli. The boundary: when AI-generated language becomes the output without significant human reshaping.
5. When Accountability Gets Diffused
Cummings (2004) established the foundational finding on automation bias: humans reduce their own monitoring and verification effort when a machine has produced an answer. The machine doesn’t add a signal. It replaces the human’s independent signal. Dressel and Farid (2018) tested the COMPAS recidivism prediction tool and found it performed no better than untrained volunteers recruited via Amazon Mechanical Turk. Because it was an “algorithm,” it was treated as authoritative. The tool introduced systematic racial bias while creating an illusion of objectivity.
PwC’s 2026 AI Agent Survey found that business leaders trust AI agents for data analysis, but confidence drops sharply for financial transactions or autonomous employee interactions. The accountability gap is felt even by leadership.
The first rule of risk management: every position has a name on it. Not the algorithm’s name. The trader’s name. When a position blows up, nobody asks what the model recommended. They ask who approved it.
When a Claude Skill produces a recommendation for Cash & Cache readers, a tool evaluation, a workflow claim, a performance number, my name is on it. The model doesn’t have a subscriber base. It doesn’t carry a reputation built over 2,000+ subscribers and 40+ posts. Accountability doesn’t transfer to a probability distribution.
When does this trade make sense? Low-stakes, easily reversible tasks. The test: could this output, if wrong, damage a relationship, mislead someone, or create a professional liability? If yes, human judgment owns the final call.
From the Library: The Second Opinion System — A 4-prompt stress test for exactly this question: when should you trust the machine, and when should you override it? →

The Three-Question Filter
Dr Sam Illingworth’s post with Frank Andrade titled The Evidence-Based Guide to AI: When to Use It, When to Stop, and How to Tell the Difference offered the most research-dense treatment of this topic I’ve read, with 17 peer-reviewed citations.

The principal underlined in the article has three questions to ponder over when you at the crossroads of AI use:
1. Am I using AI as a tool or a substitute? Tool means you shape the output. Substitute means you accept it.
2. Can I evaluate what it produces without the AI’s help? If the answer requires the same AI to check itself, you’ve lost independent judgment.
3. What am I trading away? Name the specific skill, judgment, or accountability you’re outsourcing. If you can’t name it, you haven’t thought it through.
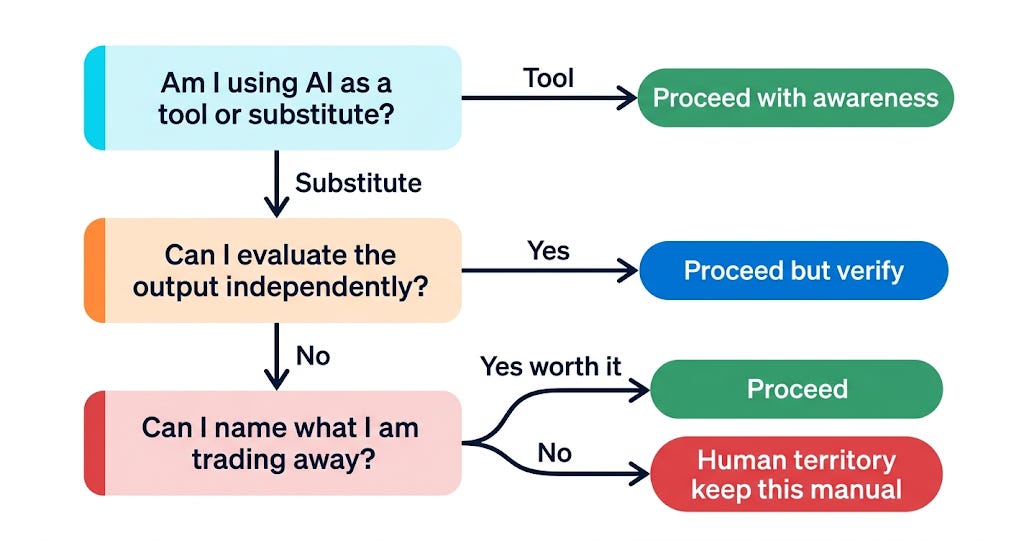
Run those three before reaching for the tool. If you can’t answer them, you’re forming a habit, not making a decision.
Where This Leaves Us
I went from managing algorithms on a trading desk to building AI workflows for a newsletter. The tooling changed completely. The job didn’t.
Know the machine. Set the boundaries. Trust the circuit breakers you built before the pressure hit.
Everything else is just faster mistakes.
💬 Over to you: What’s one task in your workflow you refuse to hand to AI? I want to hear the reasoning behind your the answer too.

This resonates — I build with it every day and still keep hard lines. Mine: the very first draft of anything where I’m still figuring out what I actually think (outsource that and you skip the thinking), any message that’s an apology or carries real emotional weight (people feel the generic instantly), and the final fact-check on anything that matters (I trust it to draft, never to be right). Funny how using it daily makes you more sure about where it doesn’t belong, not less. What’s the one line you’d never move?
The line that stuck with me was "The machine doesn't know where to stop. That's your job."
Feels like a lot of AI discussions are about capability, while the harder question is still boundaries. Not what the system can do, but what it should do without us.