

Multimodal AI Explained: How AI is Learning to See, Hear, and Think Like Humans
From 'I can't help you with that' to 'I get it'.


🧠 TL;DR
Multimodal AI is basically teaching computers to understand the world like humans do, by combining images, text, audio, and video all at once instead of just one type of input. The main challenges are getting different data types to align (like knowing a banana photo and the word "banana" mean the same thing) and figuring out how to merge everything together smartly. It costs about twice as much as regular AI, but prices are dropping fast. Companies are already using it to optimize packaging, power self-driving cars, and analyze medical scans.

👀 Unimodal to Multimodal Intelligence
While you scroll through social media, your brain is processing images, videos, and audio to understand the intricacies of each and decide what content you like. Your brain is able to seamlessly combine different types of inputs to form decisions and reactions. Multimodal AI looks to bring these capabilities to your favorite LLMs, the ability to see, hear and understand content how humans perceive.
Traditional LLMs currently excel at understanding a single mode of data input like images or text. Multimodal AI integrates the ability to develop context and understanding by synergizing learnings from multiple input methods. This helps AI build a more nuanced understanding of a topic. This is similar to how humans develop context. If you want to learn about a topic, you might watch YouTube videos, listen to podcasts, or read newsletters, all while building context and understanding on a topic.
🧩 The Core Problem Making Sense of Everything at Once
For AI systems to develop multimodal context and understanding, they must learn to seamlessly use and prioritize multiple modalities to develop a coherent understanding of the topic.
The fundamental challenge has two parts: alignment and fusion.
Alignment is like teaching AI that a picture of a banana and a text phrase containing “banana” represent the same concept, just through different modalities
Fusion involves formulating the logic of processing different modalities separately and combining them to form understanding
🔗 Alignment
There are three broad types of alignments that are relevant for business applications:
Semantic Alignment: Ensuring that different types of data are processed in a way that they converge to the same meaning. An AI learns that an angry email, frustrated voice recording and a frown all represent the same emotion: the user is not happy
Temporal Alignment: Making sure that all data streams are synchronized to the same timestamp. This ensure that the AI is using data from multiple data streams that were recorded at the same time to make decisions, so that outdated information is not used in the decision making process
Spatial Alignment: Maps different data sources to the same physical location or coordinate system. In healthcare, the AI needs to know that a message from a user describing a “sprain” and an X-ray image both refer to the same anatomical areas.
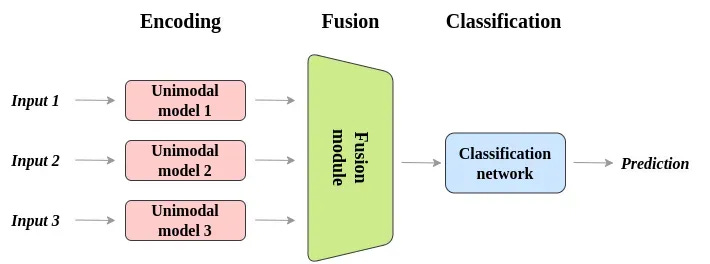
⚛️ Fusion
There are four widely accepted types of fusion and they vary
Early Fusion: Combine all data types at the input level before any processing, all the input gets processed together from the start. Concatenate all data streams into a single input which flows through one unified model architecture. Basically, like making oats, you combine all ingredients before you switch on the gas
Intermediate Fusion: Each data type will have its own specialized techniques to process data, then we combine the processed results. Each modality is converted into feature representations by dedicated encoders, then the processed features are merged and refined by additional neural network layers. Now we get more organized, separate chefs cook different parts of a meal, one for the steak, one for the fries, and combine everything during the plating.
Late Fusion: Run separate AI models for each data type, then combine their final outputs. Each modality is analyzed, processed, and scored separately through specialized pipelines for those modalities, then the outputs are aggregated through voting, averaging or another mechanism. You skip the restaurant, and order your drink from a cafe, shawarma from the middle eastern restaurant and desert from the bakery through your food delivery app, you get the best of three worlds
Attention-based Fusion: The system takes ownership, effectively deciding which modalities to prioritize based on the specific task and context. The model learns attention weights that decides how much influence each modality should have in the final output based on the context and situation. We are now inventing a new app, where you describe what you want to eat and AI figures out where to place an order from and gets it delivered to you.
Companies don’t select fusion models just based on technical sophistication, they consider the business context as well.
💰 The Cost Reality
But there’s one major concern in the road to multimodal AI, multimodal processing is fundamentally more expensive that single modality AI. The complexity arises from the need to separately process, align and fuse multiple modalities simultaneously each requiring specialized processing before integration. According to McKinsey, multimodal AI cost twice as much per token as compared to traditional LLMs.
The additional cost arises due to each data type requiring its own encoder, and cross-attention mechanisms between data modalities, larger memory footprints and extended training times.
📉 The Economics Revolution
The numbers show that the cost of using AI is decreasing steadily. In November 2022, using models like GPT 3.5 costs you around $20 per million tokens, this has dropped as low as $0.07 per million tokens as of October 2024.
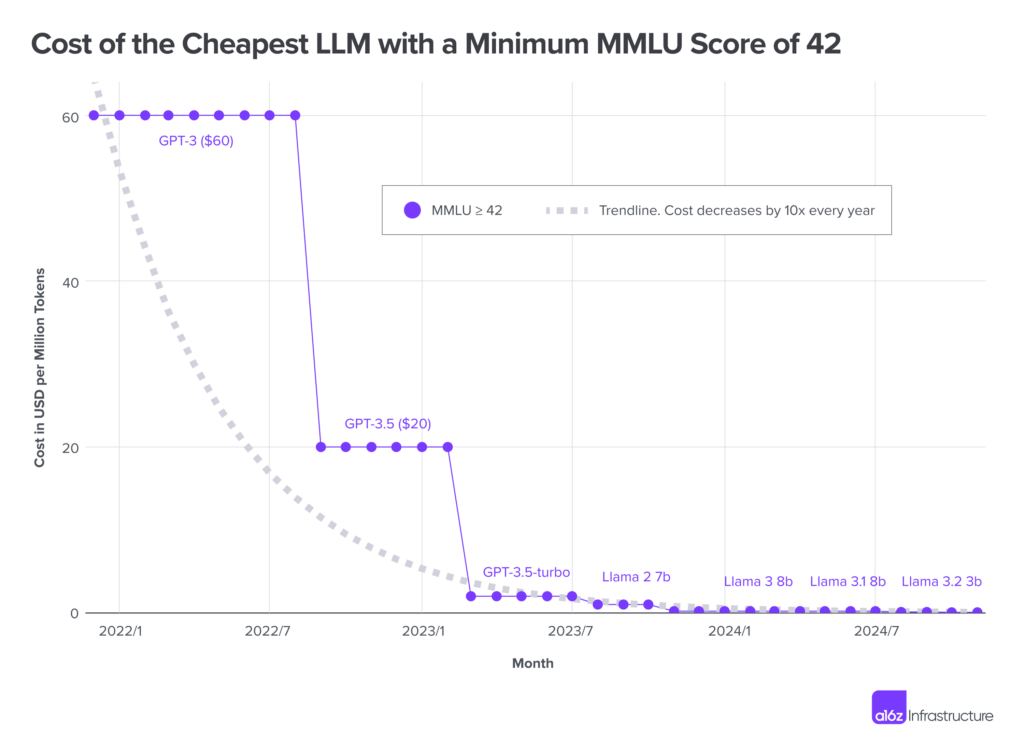
However, this is not just about cheaper cloud computing. The average cost of computing was actually expected to climb 89% between 2023 and 2025. 80 % of executives agree that this is primarily driven due to GenAI and its applications. This pressure on cost is driving organizations to drive efficiency innovation.
Edge computing helps ease the cloud bill by computing directly in the device. A new model MiniCPM-V outperformed larger LLMs like GPT-4V, Claude and Gemini Pro across 11 public benchmarks which can run efficiently on mobile phones. This model uses fusion techniques to achieve maximum performance with minimal resources.
Instead of paying hefty cloud bills, you can now compute multimodal requests locally on your device. You can create live captions on your live videos, transcribe notes from a YouTube video you are watching, all without sending a single request to the cloud.
🏭 Industry Implementations
The following use cases show how different industries are leveraging multimodal AI to drive efficiencies:
Amazon Packaging Optimization: Amazon uses multimodal AI to drive efficiencies in the packaging and material usage. Their AI analyzes product dimensions, shipping constraints, and inventory location simultaneously to make packaging and shipping decisions. Using this method Amazon has reduced the weight of outbound packages by 36% while saving 1M tons of packaging material worldwide
Healthcare: Healthcare organizations need AI models that are capable of integrating with multiple systems and use output data competently across modalities like medical imaging, genomics, and clinical records to assess patient health. Microsoft’s healthcare AU models including MedImageInsight for image analysis, MedImageParse for image segmentation (x-rays, CTs, MRIs, etc.), and CXRReportGen for automated x-ray report generation are helping hospitals transform workflows
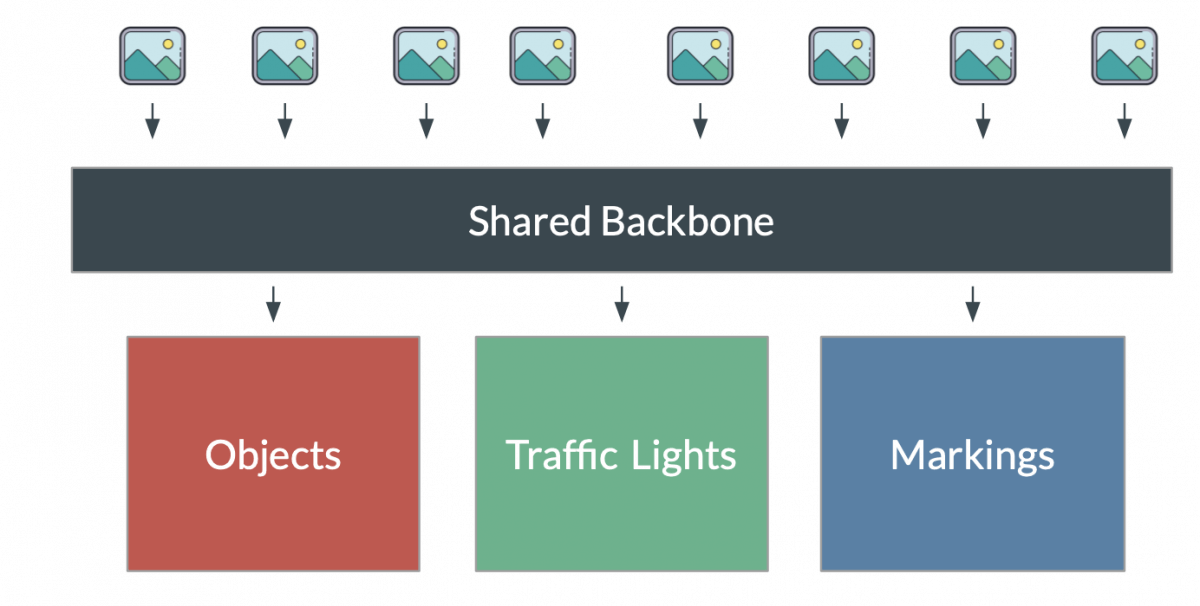
Autonomous Driving Vehicles: Autonomous vehicles like use multimodal AI to navigate the streets, combining data from computer vision, radar, GPS, LiDAR and audio. Each modality is processed through specialized pipeline and fusion algorithms combine them to make quick decisions regarding safety and navigation. Tesla, for example, uses their proprietary '“HydraNet” architecture in their cars, all images that are captured are fused using a central backbone that also redirects images to a specialized AI that processes the information annotated in each image. Tesla opts out of using LiDAR instead choosing a mix of cameras and radar for their autonomous vehicles.
💹 Investment and Tech Landscape: Who’s Building Multimodal AI
Tech is quick to board the multimodal train, OpenAI’s move to add image and voice to ChatGPT indicated that they see multimodality input as a key functionality to enhancing user experience. Google announced the Gemini family of multimodal models that are capable to processes multiple modalities directly in competition to OpenAI. Meta built ImageBind, which was the first AI model that could bind information from 6 modalities including text, image, video, audio, 3D, thermal, and others.
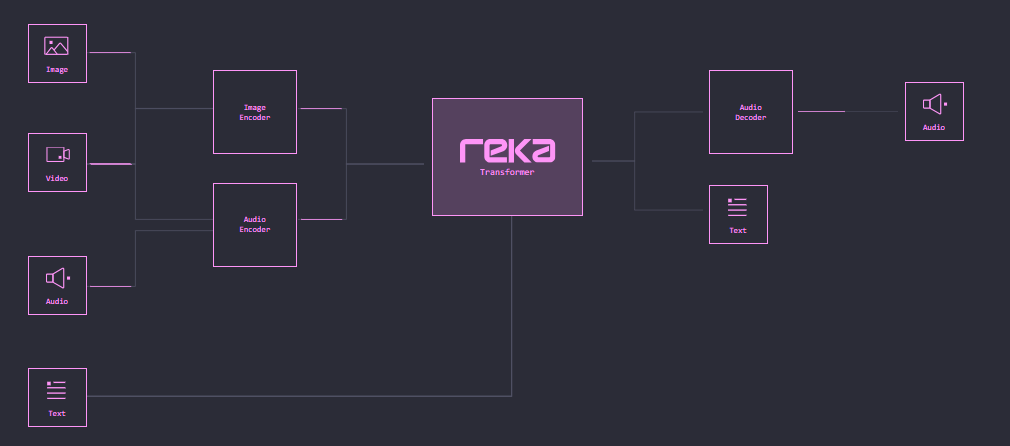
It’s not just big tech that’s playing the game, a new wave of startups are shaping the frontier of multimodal AI and raising significant VC funding in the process. In July 2025, Reka, a startup that focuses on multimodal AI platforms secured $110M in funding backed by prominent investors like NVIDIA and Snowflake. Their proprietary model the ‘Reka Flash’ is a multimodal model that can process video, image, audio and text, showcasing that startups are also able the play the game. The ecosystem is supported by open source tools and platforms like Hugging Face providing libraries for multimodal projects
🔮 How Multimodal AI Could Shape the Future
Multimodal AI brings us closer to interacting with AI as a human would. It brings you closer to AI systems that don’t just communicate but also senses your environment and takes action. Imagine selecting a destination on google maps and your car takes you there while you work in the back seat, AI sports coach telling you how to improve your golf swing, AR glasses that scan food on the table and provides you with macros. Possibilities go on.
Multimodal AI also has the potential to transform industries:
Healthcare is able to generate smart second opinions on diagnosis to support doctors with a comprehensive set of possible scenarios
Creative industries get a smart helper that can create multimedia content based on ideas
Capital markets institutions can deploy multimodal AI models that can scan press releases, public speeches, company filings making analyses more streamlined and decision-making simpler
Autonomous mobiles get smarter and safer, vehicles can analyze lighting, audio cues and video input to make smarter and safer decisions
Our world is multi-sensory, helping AI understand multiple channels of data helps AI understand concepts and context like humans. However, with this brings its own set of challenges. As AI is increasingly used for content generation we are increasingly inundated with deepfakes and misinformation. We will need to actively develop frameworks and strong governance to verify authenticity and ethical guidelines for content generation. Privacy concerns are heightened when AI is able to access multiple modalities and systems (check out our previous article to learn how synthetic data is helping remove this issue), so we must ensure that access is controlled and used responsibly.
💬 What AI use case do you think would really benefit from multimodal capabilities? Share your insights, and let’s continue the discussion.
🔎 If you found this read interesting, check out some of our similar articles:




🗞️ Interested in staying up to date with latest news around tech and business but not getting enough time?
The ‘Weekly Cache’ has you covered! It’s our weekly news digest that rounds up all the important news stories in tech, markets, and, business in a crisp, sub 5-minute read. Check it out below:


Thanks for reading Cash & Cache! Subscribe for free to receive new posts and support our work.
I’m especially fascinated by how edge computing is levelling the playing field - multimodal power without the cloud bill? That’s a shift worth watching.
L10N would benefit loads of an AI that could make the correct interpretation of strings within its visual context.